
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 쉬운 코드
- 갤럭시 S24
- recoverability
- vite
- 김영한
- 코딩애플
- B tree 데이터삽입
- concurrency control
- 백엔드
- 데이터베이스
- Git
- 시스템프로그래밍
- BreadcrumbsComputer-Networking_A-Top-Down-Approach
- 네트워크
- 프로세스 주소 공간
- 운영체제와 정보기술의 원리
- SQL
- 쉬운코드
- 코딩테스트 [ ALL IN ONE ]
- Extendable hashing
- 개발남노씨
- 온디바이스AI
- SDK
- 트랜잭션
- 커널 동기화
- 운영체제
- 반효경
- CPU 스케줄링
- 시그널 핸들러
- 인터럽트
- Today
- Total
티끌모아 태산
트랜잭션 - concurrency control 기초(1) 본문
이번 시간에는 concurrency control의 기초가 되는 schedule과 serializability에 대해서 알아보도록 하겠습니다.
Schedule
자, K라는 사람이 H라는 사람에게 20만원을 이체할 때 H도 ATM에서 본인 계좌에 30만원을 입금한다면 여러 형태의 실행이 가능할 수 있습니다.
1 case
K의 트랜잭션이 발생한 이후에 H의 트랜잭션이 발생하는 경우 입니다. 즉 K에서 read, write, commit 한 후 H에서 read, write하고 commit하는 순서입니다.

2 case
이번에는 30만원을 입금하는 트랜잭션이 먼저 발생하고 그 후에 K가 H에게 20만원을 송금하는 트랜잭션이 발생한 것입니다.

3 case
이번에는 20만원을 송금하는 트랜잭션을 먼저 시작을 했습니다. 그래서 K측에서 먼저 read, write을 하였습니다. 그러면 H에서 20만원 받은 것에 대한 read, write 과정을 거쳐야하는데, 이때 하필 ATM기에서 30만원을 입금하는 트랜잭션이 발생한 것입니다. 그래서 두 번째 트랜잭션이 완료가 된 후 이전에 처리하지 못했던 20만원에 대해서 처리하게 되는 것입니다.

4 case
이번에는 먼저 시작했던 트랜잭션이 두번 째 트랜잭션에 대한 업데이트를 하기전에 read하였기 때문에 이상한 결과가 나오게 됩니다. 즉 여러 트랜잭션이 동시에 발생함으로써 잘못된 결과를 초래한 것입니다.

이러한 현상을 LOST UPDATE라고 합니다. 즉 두 번째 트랜잭션에 대한 업데이트가 사라지게 된 것이죠! 즉, 두 번째 트랜잭션이 완료된 후에 미루었던 첫 번째 트랜잭션은 여전히 200만원이 계좌에 있다고 생각(왜냐하면 두번째 트랜잭션이 시작하기 전에 이미 read했고 앞으로 write과 commit만 남았기 때문에)합니다. 그래서 최종적으로 write을 통해 220만원이라 하고 commit을 하여 첫 번째 트랜잭션을 종료하게 됩니다.

이 처럼 경우에 따라서 여러 트랜잭션이 동시에 발생할 때 이상한 결과가 나올 수 있음을 확인하였습니다. 그리고 우리가 실행한 read, write, commit 하나하나를 operation이라고 합니다.

이 operation을 간소화 시키면 다음과 같습니다.

그럼 이렇게 간소화 시킨 operations를 타임라인으로 만들어 보겠습니다.

즉, 이는 여러 트랜잭션들이 동시에 실행될 때 각 트랜잭션에 속한 operation들의 실행 순서를 나타냅니다. 그리고 우리는 이러한 실행 순서를 Schedule 이라고 합니다.

결국 이 case 각각이 스케줄이라는 것입니다. 그리고 중요한 특징중 하나는 각 트랜잭션 내의 operation들의 실행 순서는 바뀌지 않는다는 점입니다.

조금 전에 살펴 보았듯이 case 1과 case 2는 트랜잭션들이 겹치지 않고 한번에 하나씩 실행되는 schedule입니다. 이러한 스케줄을 우리는 serializable 하다고 합니다.

반면에 case 3과 case 4는 트랜잭션들이 겹쳐서(interleaving) 실행되는 스케줄입니다. 이러한 경우를 nonserializable 이라고 합니다.

Serial schedule의 성능
한 번에 하나의 트랜잭션만 실행되기 때문에 동시성이 현저히 떨어진다. 그래서 성능이 좋지 않습니다. 왜냐하면 여러 트랜잭션을 동시에 처리할 수 없기 때문입니다. 그래서 현실적으로 사용할 수 없는 방식입니다.

그럼 이번에는 Nonserial schedule의 성능에 대해서 알아보겠습니다. I/O 작업을 하는 동안 다른 트랜잭션을 처리하느라 CPU는 놀지 않기 때문에 성능이 효율적입니다. 그래서 여러 트랜잭션을 동시에 처리할 수 있기 때문에 성능적인 측면이 좋게 됩니다.

결국, Nonserial schedule이 serial schedule보다 같은 시간 동안 더 많은 트랜잭션을 처리할 수 있기 때문입니다. 하지만 nonserial schedule에는 단점이 있는데요, 앞서 말씀드린것 처럼 트랜잭션들이 어떤 형태로 겹쳐서 실행되는지에 따라 이상한 결과가 나올 수 있습니다. case 4번이 해당됩니다.

자 그러면 우리는 이렇게 이상한 결과가 나오지 않게 하고 싶습니다. 즉,
- 성능 때문에 여러 트랜잭션들을 겹쳐서 실행할 수 있으면 좋겠다.
- 하지만 동시에 이상한 결과가 나오지 않도록 하고싶다.
그래서 nonserial schedule로 실행을 해도 이상한 결과가 나오지 않을 수 있는 방법을 생각하게 되었습니다. serial schedule은 이상한 결과는 만들지 않기 때문에 serial schedule과 동일한(equivalent) nonseiral schedule을 실행하면 되겠다! 라는 생각을 하게 되었습니다.

그러면 동일하다는 무슨 의미일까요? 우선, 두 개의 operation에 대한 conflict 개념에 대해서 알아보겠습니다. 세 가지 조건을 모두 만족하면 conflict라고 합니다.
- operation이 서로 다른 transaction에 소속
- 같은 데이터에 접근
- 최소 하나는 write operation
예를들어, schedule 3의 경우 r2(H)와 w1(H) 이 operations은 서로 다른 트랜잭션에 속하며 H라는 같은 데이터에 접근합니다. 그리고 하나가 write operation입니다. 즉 두 operation은 conflict하며 이를 구체적으로 read-write conflict라고 합니다.

다음과 같이 write-write conflict도 존재합니다.

정리해 보면 schedule 3에 대해서 보면 총 3개의 conflict가 존재함을 확인 할 수 있습니다.

그러면 conflict는 왜 중요할까요? 중요한 특징이 있습니다. 바로 conflict operation의 순서가 바뀌면 결과도 바뀐다는 특징 입니다.

순서가 바뀌었기 때문에 230만원에서 200만원으로 바뀌게 됩니다.
conflict equivalent for two schedule
다음은 두 개의 스케줄이 아래의 두 조건을 모두 만족하면 conflict equivalent 하다는 것입니다.
- 두 스케줄은 같은 트랜잭션들을 갖는다.
- 어떤(any) conflicting operations의 순서도 양쪽 스케줄 모두 동일하다.
아래의 경우는 20만원을 송금하는 트랜잭션과 ATM 기에서 30만원을 입금하는 트랜잭션을 모두 갖는 경우이기게 첫 번째 조건을 만족합니다. 그리고 스케줄 3번과 스케줄 2번의 conflicting operation의 순서가 같음을 알 수 있습니다.
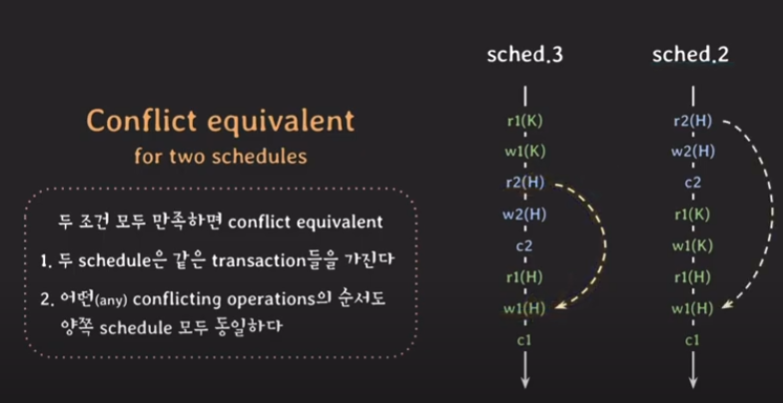
그 외 다른 모둔 conflicting operation들도 모두 같아야 합니다. 그래서 다 확인해 보셔야합니다. 그래서 확인한 결과 모두 같기 때문에 최종적으로 두 스케줄은 conflicting equivalent 하다라고 말할 수 있습니다.

자세히 보면 스케줄 2는 serial schedule입니다. 그래서 스케줄 3입장에서는 serial schedule과 conflicting equivalent한 것입니다. 이를 conflict serializable이라고 합니다. 이 개념이 매우 중요합니다.

결국, non-serial schedule이 serial schedule과 conflict equivalent 하다는 것은 최종적으로 그 해당 스케줄 여기서는 스케줄 3이 confilct serializable하다는 뜻입니다.

다음 스케줄 4와 2는 서로 같은 트랜잭션을 갖기 때문에 첫번 째 조건을 만족하지만 어떠한 conflicting operation에 대해서 다른 순서가 존재 하기 때문에 conflict equivalent하다고 할 수 없습니다. 그러나 이때 스케줄 4번이 스케줄 1번과 conflicting equivalent하다면 스케줄 4는 conflict serializable하다고 할 수 있습니다. 하지만 스케줄 1번과 어떤 conflict operation에 대해서 다른 순서 값을 갖기 때문에 최종적으로 스케줄 4는 conflict serializable 하지 않다하고 할 수 있습니다.


정리를 하면 성능 때문에 여러 트랜잭션을 겹쳐서 실행하고 싶습니다. 그런데 이상한 결과로 인해서 문제가 있었습니다. 하지만 이제는 해결책으로 conflict serializable한 nonserial schedule을 사용하는 것입니다. 그러면 또 다른 이슈가 있습니다. 자 우선 해결책을 찾았으니 그럼 저걸 어떻게 사용할까요? 먼저 여러 트랜잭션이 실행될 때 마다 해당 스케줄이 conflict serializable한지 check해야합니다. 하지만 이 방식은 요청이 많이 몰려오면 동시에 실행될 수 있는 트랜잭션이 너무 많기 때문에 그 수많은 트랜잭션에 대해서 그 스케줄이 conflict serializable한지 확인 할 수 없습니다. 그래서 구현해서 사용하기 보다는 여러 트랜잭션을 동시에 실행 해도 스케줄이 conflict serializable하도록 보장하는 프로토콜을 적용하는 방식을 사용하게 됩니다.
결국 하나하나 확인하는 방식보다는 아예 처음부터 conflict serializable한 스케줄만 실행할 수 있도록 프로토콜을 활용하는 것입니다.
- 어떤 스케줄이 (serial schedule or nonserial schedule) 어느 한 serial schedule과 conflict equivalent(1. 두 스케줄이 같은 트랜잭션 갖음 2. 어떤 conflicint operation에 대해서 같은 순서를 갖음) 하다면 이는 그 스케줄이 conflict serializable 하다 혹은 conflict serializability를 갖는다 라고 할 수 있습니다.
- 추가적으로 어떠한 스케줄도 serializable하게 만드는 것이 바로 concurrency control입니다. 그리고 이와 관련된 속성이 isolation입니다. *지나친 isolation은 동시성이 사라지기 때문에 성능이 떨어지게 됩니다.
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| 트랜잭션 - concurrency control 기초(2) (0) | 2023.12.09 |
|---|---|
| DB - transaction (1) | 2023.12.07 |
| DB - indexing(2) (1) | 2023.12.05 |



