
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 개발남노씨
- 김영한
- 백엔드
- 운영체제
- BreadcrumbsComputer-Networking_A-Top-Down-Approach
- vite
- concurrency control
- 운영체제와 정보기술의 원리
- B tree 데이터삽입
- 쉬운코드
- 데이터베이스
- 커널 동기화
- 갤럭시 S24
- 시그널 핸들러
- 트랜잭션
- SQL
- 인터럽트
- recoverability
- 반효경
- Extendable hashing
- 코딩애플
- 네트워크
- 쉬운 코드
- 시스템프로그래밍
- 프로세스 주소 공간
- Git
- CPU 스케줄링
- 코딩테스트 [ ALL IN ONE ]
- 온디바이스AI
- SDK
- Today
- Total
티끌모아 태산
DB - Indexing 본문
이번 시간에는 데이터베이스에서 index가 중요한 이유와 동작 방식 등에 대해서 알아보도록 하겠습니다.
Indexing
다음과 같이 쿼리문이 있다고 생각해 보겠습니다. 현재, customer table은 아래와 같이 구성되어 있고, 데이터의 수가 100만개라고 가정해 보겠습니다.
SELECT * FROM customer WHERE first_name = 'Minsoo';
이때, first_name에 index가 걸려있지 않다면 성능은 어떻게 될까요?! index가 걸려 있지 않다면 first_name이 'Minsoo'인 것을 찾기위해 100만개의 데이터를 모두 탐색해야합니다. 이렇게 하나하나 모두 다 확인하는 것을 Full scan or table scan이라고 합니다. 그리고 시간복잡도는 데이터의 개수가 N개라고 할 때, O(N)의 시간이 걸립니다. 하지만, 만약 index가 걸려있다면?! full scan보다 더 빨리 데이터를 찾을 수 있습니다. 그리고 시간 복잡도 역시 데이터의 개수가 N개라고 할 때, O(logN) (B-tree based index) 따라서 쿼리 문을 더 빠르게 처리할 수 있습니다. 즉, 성능이 향상된 것입니다.
결국, 우리가 index를 사용하는 이유는 다음과 같습니다.
- 특정 조건을 만족하는 튜플(들)을 더 빠르게 조회하기 위해
- 추가적으로 빠르게 정렬(order by)하거나 그룹핑(group by) 하기 위해
예를들어, 다음과 같은 쿼리문이 있다고 가정해 보겠습니다. 아래 쿼리 문들은 WHERE 절과 JOIN 절을 통해 조건이 걸려 있음을 알 수 있습니다. 그래서 해당 조건을 만족하는 데이터를 빠르게 찾기 위해 index를 사용한다고 생각하면 좋을 거 같습니다.
SELECT * FROM customer WHERE first_name = 'Minsoo';
DELETE FROM logs WHERE log_datetime < '2022-01-01';
UPDATE employee SET salary = salary * 1.5 WHERE dept_id = 1001;
SELECT * FROM employee E JOIN department D ON E.dept_id = D.id;
또, PLAYER 테이블을 살펴 보겠습니다. index를 만들기 위해 해당 테이블을 바탕으로 다음과 같은 쿼리가 있다고 생각해 보겠습니다. (테이블에는 이미 데이터가 들어있다고 가정하겠습니다.)
SELECT * FROM player WHERE name = 'Sonny';
SELECT * FROM player WHERE team_id = 105 and backnumber = 7;
먼저, name 속에 대해서 index를 걸어주겠습니다. name은 중복된 이름이 있을 수 있기 때문에 중복을 허용하는 index를 걸어 주어야합니다. mySQL을 기준으로 다음과 같이 작성해 주면됩니다.
CREATE INDEX player_name_idx ON player (name);CREATE INDEX (인덱스 이름) ON 테이블 (속성);이렇게 쿼리문을 작성하면 name 속성에 index가 걸리게 됩니다. 그럼 두번째 쿼리에 대해서 index를 걸어주는 작업을 해보겠습니다. 서로 다른 팀에서는 같은 등번호를 가질 수 있지만, 같은 팀에서는 같은 번호를 가질 수 없습니다. 그래서 team_id and backnumber를 함께 묶어 줌으로써 튜플들을 UNIQUE 하게 식별할 수 있습니다.
CREATE UNIQUE INDEX team_id_backnumber_idx ON player(team_id, backnumber);이 쿼리문은 두 개의 속성값을 묶어서 index를 걸어 주었습니다. 지금까지는 PLAYER table에 이미 데이터가 들어있다는 가정하게 index를 걸어주었습니다. 그러면 테이블을 생성할 때 즉, 테이블을 생성하는 시점에 index를 걸어주는 방법에 대해서 알아 보겠습니다. 이제 PLAYER 라는 table을 생성한다고 했을 때,
CREATE TABLE player (
id INT PRIMARY KEY.
name VARCHAR(20) NOT NULL,
team_id INT,
backnumber INT,
// 그리고 player_name_idx를 꼭 명시하지 않아도 자동으로 이름을 만들어 줍니다.
INDEX player_name_idx (name), // name은 중복이 가능해서 UNIQUE를 넣지 않았다.
INDEX UNIQUE team_id_backnumber_idx (team_id, backnumber) // UNIQUE
);
이렇게 테이블을 생성할 때 index를 걸어 줄 수 있습니다. 그리고 두 개의 속성(team_id, backnumber)을 묶어서 index 하는 것을 multiple index or composite index 라고합니다.
*그리고 대부분의 RDBMS에서는 PRIMARY KEY에 대해서 자동으로 index를 생성해 줍니다. 그러면 테이블에 어떤 index들이 걸려있는지 확인하려면?
SHOW INDEX FROM player;이렇게 아래에 중요한 정보를 알려 줍니다. 아래를 보면 Key_name에 team_id_backnumber_idx가 중복이 되는 것을 확인 할 수 있는데요, Seq_in_index를 살펴보면 순차적으로 1,2가 나오는 것을 보고 multi-column index라는 것을 파악할 수 있습니다.

B-tree 기반의 index가 동작하는 방식
이제, B-tree 기반의 index가 동작하는 방식에 대해서 살펴보겠습니다. 다음과 같이 MEMBERS라는 테이블이 있다고 해보겠습니다.

이런 상황에서 a 속성에 대해서 index를 걸어주면 다음과 같이 index가 생성됩니다. B-tree based INDEX(a)는 a속성과 pointer 데이터가 있습니다. 그리고 a에 대한 값들은 정렬되어 있음을 확인 할 수 있습니다. 또한 pointer 데이터는 실제 MEMBERS의 튜플을 가리키는 연결 고리를 담당합니다.

이런 상황에서 WHERE a = 9; 인 튜플을 찾아보겠습니다.
- 먼저, INDEX(a)를 확인합니다. 이때, 어떻게 찾냐면 데이터들이 이미 정렬이 되어 있기 때문에 'binary search'를 통해 찾습니다.
- 먼저 가운데 값을 기준으로 target value와 대소 비교를 합니다. 그런데 9가 5보다 더 크기 때문에 5보다 작은 값들은 버리게 됩니다.

그러면 위쪽 부분에서 또 가운데 지점을 선택하고 위 과정을 반복합니다. 여전히 9가 7보다 더 크기 때문에 아래 데이터는 제외합니다.

그럼 이제 9를 선택했습니다. 그럼 9와 9는 동일하기 때문에 만족하는 조건을 찾은 것입니다.

그래서 9의 포인터 데이터를 통해 실제 튜플을 찾게 됩니다.
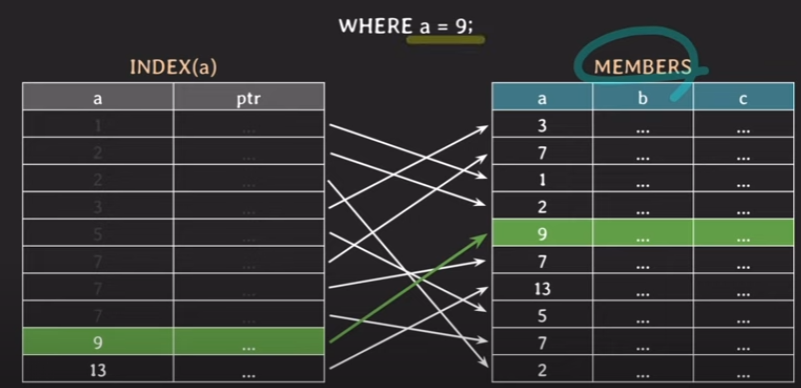
여기서 끝나는 것이 아닙니다. 실제 a = 9 인 데이터가 하나 이상일 수 있기 때문에 그 위 쪽 범위를 살펴봐야합니다. 하지만 위쪽 데이터의 첫번째가 13이고 이는 9보다 크기 때문에 더 이상 찾을 필요가 없음을 알게 됩니다. 그래서 최종적으로 튜플을 찾게 된 것입니다.

이제는 조건이 바뀌어서 WHERE a = 7 and b = 95; 라고 하겠습니다. 이때, index(a)를 그대로 사용한다고 하였을 때, 위 과정과 마찬가지로 a를 기준으로 먼저 찾게 됩니다. 이진 탐색을 통해 a = 7인 데이터를 찾았다고 해보겠습니다. 하지만 b = 95인 조건도 만족해야합니다. 그런데 현재 index는 a만 걸려 있기 때문에 b = 95 인 데이터를 찾기 위해서는 실제 MEMBERS 테이블에서 데이터를 하나하나 확인하면서 찾아야 합니다. 즉, a에 대해서는 index를 통해 찾지만 b는 full-scan을 통해 찾아야 합니다.

그리고 a = 7인 값이 여러개 있기 때문에 나머지 부분에 대해서도 다 확인을 해주어야 합니다. 우선은, 첫번 째 a= 7인 경우에 대해서 b에 대해 full-scan을 진행해 보겠습니다.
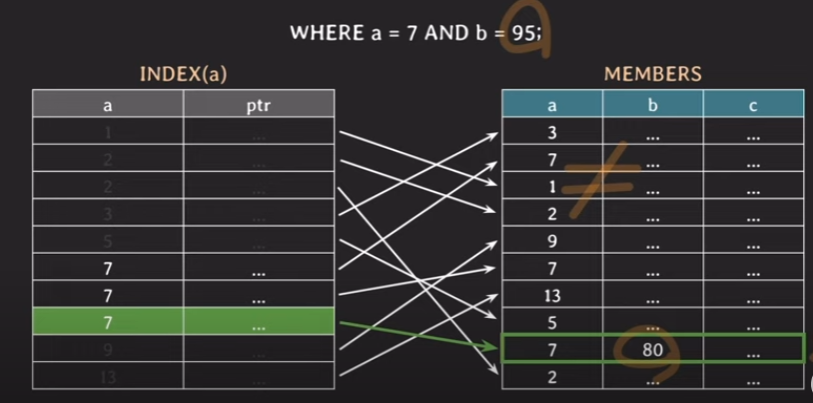
b값이 동일하지 않기 때문에 이어서 다른 튜플을 확인해야 합니다.

이제는 b의 값도 같기 때문에 해당 튜플이 선택됩니다. 하지만 a=9 and b=95인 튜플은 하나 이상일 수 있기 때문에 모든 경우에 대해서 살펴보야 합니다.

찾으려는 조건에 부합하지 않기 때문에 제외합니다. 즉 저 튜플은 선택되지 않게 됩니다. 그래서 결국, 최종적으로 아래와 같은 튜플이 선택되게 됩니다.

조금전에 말씀 드렸듯이 조건이 2개 이상일 때, a의 조건을 만족하는 값은 index가 걸려 있기 때문에 이진 탐색을 통해 데이터를 빠르게 찾을 수 있습니다. 하지만 b에 대해서는 index에 걸려 있지 않기 때문에 full-scan을 해야 합니다.

full-scan는 성능적으로 비효율적이 때문에 a와 b를 하나로 묶은 index가 존재 해야 합니다.
CREATE INDEX a_b_idx ON MEMBERS (a, b)
이제는 a뿐만 아니라 b에 대해서도 index가 있기 때문에 full-scan을 할 필요가 없습니다. 이때, 주목할 점은 첫 번째 인자를 기준으로 먼저 정렬이 진행되고 그 다음 b가 정렬이 진행됩니다. 즉 a값이 같으면 b에서 정렬이 다시 일어나게 됩니다.

이제는 새롭게 만들어진 index(a,b)를 갖고 조건에 부합하는 튜플을 찾도록 하겠습니다. 과정은 이진 탐색으로 똑같이 진행됩니다.

이진 탐색으로 찾은 튜플이 조건에 부합하기 때문에 바로 튜플을 선택합니다. 하지만 이때 그냥 끝낼 것이 아니라 해당 조건을 만족하는 튜플이 여러개 있을 수 있기 때문에 나머지 범주에 대해서도 탐색을 해보아야합니다. 위쪽은 a와 비교해봤을 때 더 값이 크기 때문에 범주에서 제외합니다. 아래쪽은 a가 모두 같기 때문에 b를 비교하게 됩니다. 그래서 최종적인 결과를 얻을 수 있게 됩니다.

이렇게 새로운 index를 만들어서 조회를 했을 때 성능이 더 좋음을 확인 할 수 있었습니다. 그러면 이제 WHERE b = 95;일때는 어떻게 될까요?
이런 경우는 성능이 나오지 않습니다. 왜냐하면 b를 단독으로 봤을 때는 정렬이 되어 있지 않기 때문에 결국에 full-scan을 하는 것과 마찬가지 입니다. 그래서 index를 살펴보나 MEMBERS를 직접살펴보나 별 차이가 없게 됩니다.
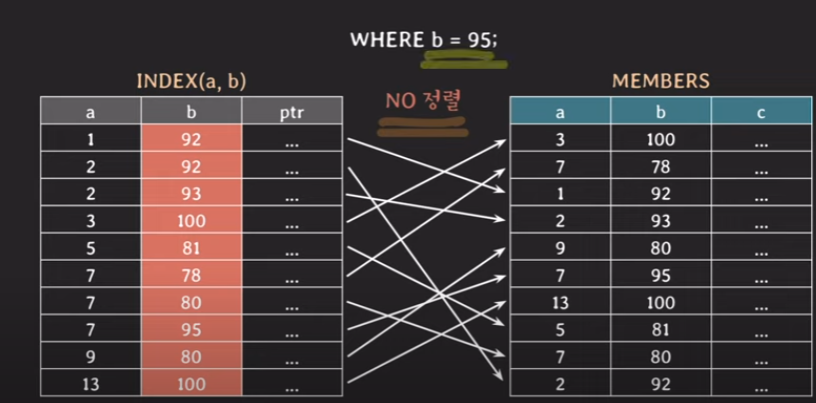
그래서 성능을 좋게 하기 위해서 b에 대해 따로 index(b)를 만들어 주어야 합니다.

그러면 이제는 b에 대한 데이터가 정렬이 되어 있기 때문에 이진 탐색을 통해 튜플을 찾을 수 있습니다.

EXAMPLE
지금까지의 예제를 통해 B-tree 기반의 index를 살펴보았습니다. 지금까지 배운 내용을 바탕으로 하나의 예제를 살펴보겠습니다. 다음과 같이 PLAYER table이 있다고 가정하고 속성에 대해 index가 다음과 같이 걸려 있다고 해보겠습니다.

이런 상황에서 다음 두개의 쿼리문을 수행한다고 해보겠습니다. 그럼 각각의 쿼리는 어떤 인덱스를 사용할까요?
SELECT * FROM player WHERE team_id = 110;
SELECT * FROM player WHERE team_id = 110 AND backnumber = 7;첫 번째 쿼리는 조건이 team_id 이기 때문에 세 번째 index를 사용할 수 있습니다. 아까 테이블을 생성할 때, team_id를 먼저 적어주고 backnumber를 그 다음에 적어줬기 때문에 1차적으로 index가 team_id를 기준으로 먼저 정렬이 되어있습니다. 그래서 해당 인덱스를 사용해서 쿼리를 빠르게 처리할 수 있습니다.
두 번째 쿼리 역시 조건 속성이 모두 세 번째 index에 포함되어 있기 때문에 빠르게 쿼리를 처리 할 수 있습니다. 그럼 다음 쿼리는 어떻까요?
SELECT * FROM player WHERE backnumber = 7;
SELECT * FROM player WHERE team_id = 110 OR backnumber = 7;먼저, 첫 번째 쿼리의 경우 세 번째 index를 사용할 수 없거나 사용하더라고 성능이 굉장이 좋지 않게됩니다. 왜냐하면 backnumber는 정렬이 되어 있지 않기 때문에 Full-Scan을 해야하기 때문입니다. 그래서 해결책으로 backnumber에 대한 index를 생성해 주어야합니다.
두 번째 쿼리 역시 team_id에 대해서는 세 번째 index를 사용해서 빠르게 처리할 수 있지만 backnumber는 Full-scan을 해야하기 때문에 성능이 좋지 않게 됩니다. 그래서 추가적으로 backnumber에 대해서 index를 만들어 주어야 합니다.

결국, 사용되는 쿼리에 맞춰서 적절하게 index를 걸어줘야 쿼리가 빠르게 처리 될 수 있습니다.
그래서 실무에서 개발할 때도 쿼리 성능이 너무 안나온다 싶으면 해당 쿼리의 index가 적절하게 걸려있는지 확인해 볼 필요가 있습니다. 그럼 index를 많이 걸어주면 좋은건가?
그럼 저렇게 index가 여러개 있는데, 어떤 인덱스를 쓰면 좋을지 궁금할 수 있습니다. 그러면 EXPLAIN을 통해 어떤 인덱스가 쓰여지는지 확인 할 수 있습니다.
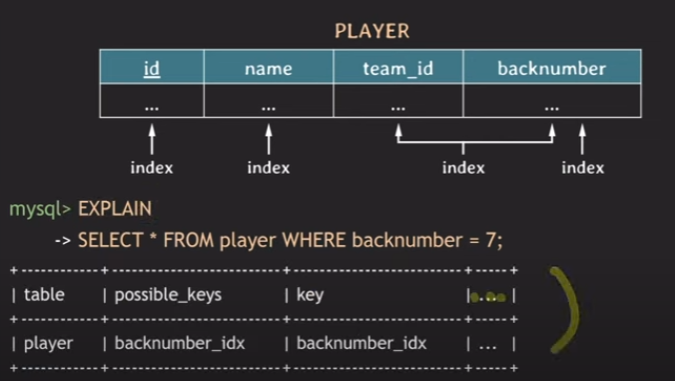
그러면 나는 어떤 index를 사용할 지 직접 명시하지 않았는데, 어떻게 선택이 된 것일까요? 이는 대부분의 RDBMS에 존재하는 optimizer가 알아서 적절하게 index를 선택하게 됩니다. 그런데 간혹 이상한 선택을 할 수 있어서 직접 특정 인덱스를 사용할 수 있도록 명시할 수 있다.

SELECT * FROM player USE INDEX (backnumber_idx) WHERE backnumber = 7; // 권장 사항
SELECT * FROM player FORCE INDEX (backnumber_idx) WHERE backnumber = 7; // 강력 사항*추가적으로 특정 인덱스를 제외하고 싶을 때는 IGNORE INDEX를 사용하면 됩니다.
Index는 막 만들어도 괜찮을까? NO!
- table에 write할 때 마다 index도 변경 발생
- 추가적인 저장 공간 차지 -> overhead 발생!
- 불피요한 index를 피하자!

Covering index

SELECT team_id, backnumber FROM player WHERE team_id = 5;teadm_id와 backnumber는 INDEX에 모두 포함되어 있기 때문에 PLAYER 테이블까지 찾아가서 튜플을 조회할 필요 없이 INDEX(team_id, backnumber)에서 조건을 만족하는 튜플을 찾을 수 있기 때문에 성능이 더 좋다. 따라서 커버링 인덱스는 실제 테이블에 가지 않고도 인덱스만드로 튜플을 찾을 수 있다. 그래서 조회하려는 속성들이 모두 index에 포함되어 있다면? Covering index
- 조회하는 attribute(s)를 index가 모두 cover 할 때
- 조회 성능이 더 빠름
Hash index
- hash table을 사용하여 index를 구현
- 시간 복잡도 O(1)의 성능
- 하지만 rehashing에 대한 부담! 즉, array를 활용해서 데이터를 저장하는데, 데이터가 커지면 hash table의 사이즈를 늘려줘야 합니다.
- equality 비교만 가능 따라서 range 비교는 불가능 합니다. 즉, =, != 이런것만 가능. < >= 이런거 불가능
- multicolumn index의 경우 전체, attributes에 대한 조회만 가능합니다. 즉 Index(a, b)를 만들었을 때, a따로 b따로는 불가능 하고 (a,b)전체에 대해서만 조회가 가능합니다. 즉, B-tree 기반의 index는 a만을 조회하고 싶을 때 index(a,b)를 사용할 수 있는데 hash index는 그렇게 사용하는 것이 불가능합니다.
Full-scan이 더 좋은 경우
- 테이블에 데이터가 조금 있을 때, (몇 십, 몇 백건 정도?)
- 그럼 데이터가 엄청 많아 졌을때는? 조회하려는 데이터가 테이블의 상당 부분을 차지할 때!

그럼 Full scan을 사용할 지 인덱스를 사용할 지 누가 결정하나요? RDBMS의 optimizer가 결정하게 됩니다.
그 외
- order by or group by에도 index가 사용될 수 있습니다.
- foreign key에는 index가 자동으로 생성되지 않을 수 있습니다.(join관련)
- 이미 데이터가 몇 백만 건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 몇 분이상 소용될 수 있고 DB 성능에 안좋은 영향을 줄 수 있습니다.
- 그래서 트래픽이 적은 상황에서 index를 사용하는 것이 좋다.
지금까지 DB에서의 index에 대해서 배워보았습니다. 감사합니다.
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| DB - indexing(1) (2) | 2023.12.05 |
|---|---|
| Data Analytics (0) | 2023.11.12 |
| Big Data and Hadoop (0) | 2023.11.11 |



