
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 반효경
- 코딩애플
- 갤럭시 S24
- 시그널 핸들러
- 개발남노씨
- 쉬운 코드
- Extendable hashing
- 운영체제와 정보기술의 원리
- vite
- BreadcrumbsComputer-Networking_A-Top-Down-Approach
- 프로세스 주소 공간
- recoverability
- 데이터베이스
- CPU 스케줄링
- 백엔드
- B tree 데이터삽입
- 운영체제
- 김영한
- 트랜잭션
- 쉬운코드
- 인터럽트
- SDK
- concurrency control
- 코딩테스트 [ ALL IN ONE ]
- Git
- SQL
- 온디바이스AI
- 시스템프로그래밍
- 네트워크
- 커널 동기화
- Today
- Total
티끌모아 태산
Relational Database Design(3) - Normalization(정규화) 본문
이번시간에는 FD를 사용해서 DB를 정규화하는 방법에 대해서 배워보도록 하겠습니다. *이상현상을 없애려면? 테이블을 분해! 따라서 정규화는 곧 관련있는 속성들로만 릴레이션을 구성하기 위해 릴레이션을 관심사별로 분리하며 함수적 종속성을 판단하여 진행한다.
정규화 = 릴레이션 분리 + 함수 종속성 판단
DB 정규화(normalization)
데이터 중복과 insertion, update, deletion anomaly를 최소화 하기 위해 일련의 normal forms(NF)에 따라 relational DB를 구성하는 과정입니다. 이때, Normal froms는 정규화 되기 위해 준수해야하는 몇 가지 rule들이 있는데 이 각각의 rule을 normal form(NF)이라고 합니다. 정규화 과정에서 주의해야할 점은 정규화를 통해 릴레이션(테이블)은 무손실 분해 되어야합니다. 즉, 분해로 인해 정보 손실이 발생하지 않아야 하며 분해된 릴레이션들을 natural join하면 분해 전의 릴레이션으로 복원 가능해야합니다.

가령, 3NF을 만족한다면 이미 1NF와 2NF를 만족했다는 뜻입니다. 그리고 보통은 3NF까지 도달하면 정규화 됐다고 하는 것이 일반적입니다. 5NF나 6NF는 굉장히 복잡하기도하고 연구 목적으로 다루는 경우가 많습니다. 따라서 실무에서는 보통 3NF와 BCNF까지만 정규화를 진행합니다.
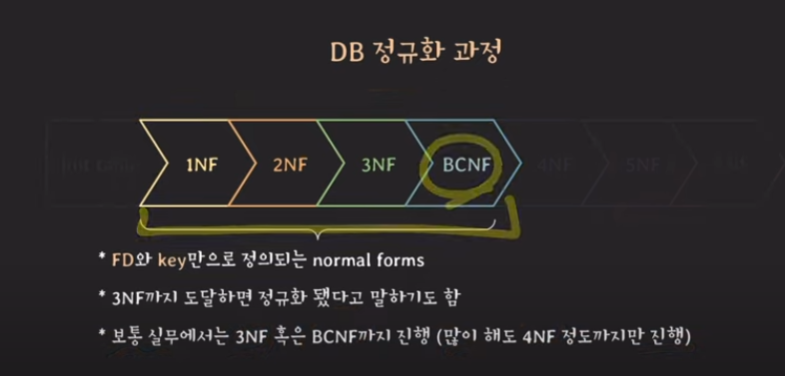
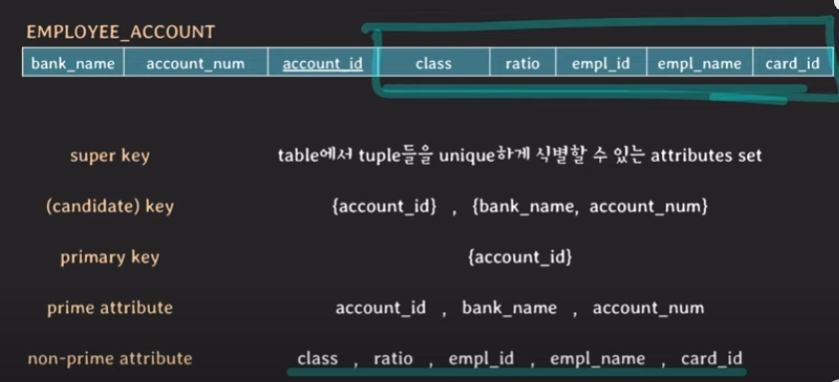
BCNF까지가 FD와 KEY만으로 정의되는 normal forms입니다. 그럼 다음 예시를 살펴보겠습니다.EMPLOYEE_ACCOUNT는 총 7개의 attributes로 구성되어 있습니다.

KEY
- super key: 테이블에서 튜플들을 unique하게 식별할 수 있는 attributes set입니다.
- (candidate) key: 어느 한 attributes라도 제거하면 unique하게 튜플들을 식별할 수 없는 super key입니다. 가령, {account_id}는 그거 자체로 unique하기 때문에 super key 임과 동시에 candidate key입니다. 또 다른 candidate key를 살펴보면 {bank_name, account_num} 있는데, 이때 두 속성이 함께 있으면 후보 키와 동시에 수퍼 키가 되지만 이 중 하나라도 없으면 튜플들을 구별할 수 있는 unique 함이 사라지기 때문에 candidate 키 입니다.
- primary key: 테이블에서 튜플들을 unique하게 식별하려고 선택된 candidate key, 가령 후보 키는 {account_id}, {bank_name, account_num} 있는데, 이 중에서 하나를 선택하면 그 선택된 것이 primary key가 됩니다. 일반적으로 attribute 수가 더 적은것이 관리하기가 편하기 때문에 account_id를 선택합니다.
*prime attribute - 임의의 key에 속하는 attribute. 예를들어, key는 {account_id}, {bank_name, account_num} 이 있는데 여기에 속하는 속성들인 account_id, bank_name, account_num 이 prime attribute가 됩니다. 그러면 여기에 속하지 않는 즉, prime attribute에 속하지 않는 모든 속성들을 non-prime attribute라고 합니다. 즉, 어떠한 key에도 속하는 않는 속성들!
그럼 이제 functional dependency를 살펴보면, primay key인 account_id는 다른 모든 속성들을 결정합니다. 이렇게 left-hand side에 속하는 것은 사진과 같이 ㅣ 에 표시하고 나머지 right-hand side에 속하는 것들은 화살표를 사용합니다. 따라서 functional dependency를 아래와 같이 시각화 할 수 있습니다.

또한, {bank_name, account_num} 역시 다머지 속성들을 결정할 수 있습니다. 게다가 empl_id는 empl_name를 결정합니다. 또 살펴보면 은행별로 등급이 겹치지 않기 때문에 class -> bank_name 으로 나타낼 수 있습니다.

이제 본격적으로 정규화에 대해서 알아보도록 하겠습니다. 보통은 스키마를 통해 정규화를 진행하지만 다음과 같이 데이터를 포함해서 알아보도록 하겠습니다.

1NF
attribute의 value은 반드시 나눠질 수 없는 단일한 값이어야 합니다. 위 데이터에서 card_id가 c201, c202를 각각 나눌 수 있기 때문에 1NF를 위반하고 있는 것입니다. 그래서 처리를 해줘야지 다음 단계로 나갈 수 있다. 예를들어 다음과 같이 처리했다고 해봅시다.



1NF를 만족시켰지만 다음과 같이 중복된 데이터가 생기고 ratio도 수정해야하며, primary key도 변경을 해줘야합니다. 왜냐하면 card_id를 나눴더니 account_id가 a21, a21로 동일하기 때문에 unique함을 잃어버리게 되었습니다. 그래서 card_id도 primary key로 만들어주어야 합니다.
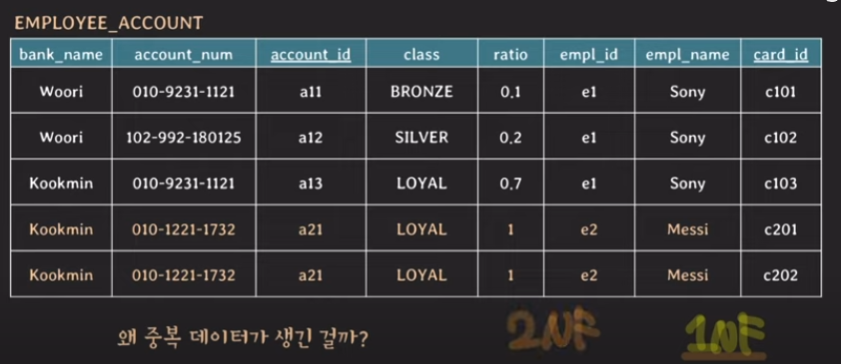
이전에는 {account_id}, {bank_name, account_num}이 candidate key였는데, 이제는 card_id를 각각 추가해줘야지만 튜플들을 unique하게 식별할 수 있습니다.

예를들어, {account_id, card_id}는 나머지 속성들을 결정할 수 있습니다.

non-prime attribute를 살펴보면 {account_id, card_id}에 의존하는 것을 확인할 수 있는데 과연 account_id와 card_id모두에게 의존해야할까요?

사실, account_id 만으로도 non-prime attribute들을 결정할 수 있습니다. 따라서 이런 관계를 다음과 같이 말합니다. 모든 non-prime attribute들이 {account_id, card_id}에 partially dependent 하다

이번에는 또 다른 (candidate) key를 살펴보겠습니다.

이때도, non-prime attribute들이 {bank_name, account_num}에 의해서 결정될 수 있기 때문에 partially dependent 하다고 말할 수 있습니다.

그래서 이러한 partially dependent를 해결하기 위해서 2NF가 등장하게 되었습니다.

2NF
모든 non-prime attribute는 모든 key에 fully functionally dependent 해야합니다. 위 데이터는 이를 위반하고 있는데 그 이유는 card_id를 primary key로 만들어 주었기 때문입니다. 그래서 다음과 같이 card_id를 따로 분리하는 방법을 사용합니다. 그래서 중복되는 나머지 하나를 제거해서 2NF를 만족하게 만듭니다. 아래와 같이 ACCOUNT_CARD 테이블에 account_id와 card_id 속성을 만들어 줍니다. account_id를 함께 적어주는 이유는 EMPLOYEE_ACCOUNT 테이블과 연결고리가 있어야하기 때문(JOIN 등 사용)입니다.



이런식으로 따로 분리 하고 EMPLOYEE_ACCOUNT에서는 card_id부분을 제거합니다.

그리고 중복된 튜플을 하나 삭제해서 유니크 하게 만들어 줍니다.

이제 2NF를 만족하는지를 살펴보면 account_id에 non-prime attributes인 class, radio, empl_id, empl_name이 account_id에 partially 가 아니라 fully 하게 dependent 하기 때문에 2NF를 만족하게 됩니다. 다른 candidate key를 살펴봐도 마찬가지로 만족합니다.

따라서 다시한번 리마인드하면 2NF은 모든 non-prime attribute는 모든 key에 fully functionally dependent 해야합니다.
이렇게 함으로써 1NF와 2NF를 만족하게 됩니다. 다음시간에는 나머지 정규화 과정에 대해서 배워보도록 하겠습니다.
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| Relational Database Design(4) - Normalization(정규화) (0) | 2023.11.08 |
|---|---|
| Relational Database Design(2) - functional dependency(함수 종속) (0) | 2023.11.07 |
| SQL 데이터 조회: group by, aggregate function, order by (1) | 2023.09.19 |



