Big Data and Hadoop
이번 시간에는 빅데이터와 Hadoop 개념에 대해서 간단히 알아보도록 하겠습니다.
Big data
Big data 출현 배경
먼저, 빅데이터는 인터넷과 모바일 확산으로부터 다양한 대규모의 데이터 발생과 데이터의 방대한 활용성 등으로 인해서 출현하게 되었습니다. 예를들어, IoT 기기의 확산은 대량의 데이터를 발생시켰고 이러한 방대한 양의 데이터를 어떻게 효율적으로 처리하고 관리하기 위한 연구가 활발히 진행되고 있습니다.
Big data란
빅데이터는 기존 데이터베이스 관리도구로 데이터를 수집, 저장, 관리, 분석할 수 있는 역량을 넘어서는 대량의 정형 또는 비정형 데이터를 저장하고 이로부터 가치를 추출하고 결과를 분석할 수 있는 기술을 의미합니다. 쉽게 말해, 다양한 종류의 대규모 데이터로부터 원하는 데이터를 빠르게 수집, 분석을 통해 가치 추출을 지원하도록 고안된 차세대 기술 및 아키텍처입니다. 이러한 빅데이터는 다양한 분야 (정치, 경제, 경영 과학) 에서 활용되고 있습니다.
- 정형 데이터: 데이터베이스, 사무정보
- 비정형 데이터: 이메일, 멀티미디어, SNS
Hadoop
하둡이란 빅데이터 분산 처리/분석 오픈소스 데이터 관리 플랫폼입니다. 이 플랫폼은 서버를 이용하여 가상화 된 HDFS를 구성하고 거대한 데이터를 간편하게 다루는 MapReduce 프레임 워크를 구현하여 제공합니다. 결국 Hadoop이란 빅데이터를 분산 저장(HDFS) + 분산 처리(MapReduce)를 하는 데이터 관리 플랫폼입니다.
HDFS(Hadoop Distributed File System)
HDFS는 대용량 파일의 저장과 처리를 위한 분산 처리 시스템입니다. 이때 대규모의 데이터를 여러 대의 서버에 나눠서 저장합니다.

HDFS FILE WRITE(쓰기)
일반적으로 원본데이터 1개와 복사본 데이터 2개 그래서 총 3개를 3곳에 저장을 하게 됩니다. 여러대의 서버 묶음을 Rack이라고 하며 복사본은 백업용으로 사용하게 됩니다.

- 먼저, Hadoop Client는 Name Node에게 데이터(A)의 저장 요청을 보냅니다. 여기서 Name Node는 매니저 역할을 합니다.
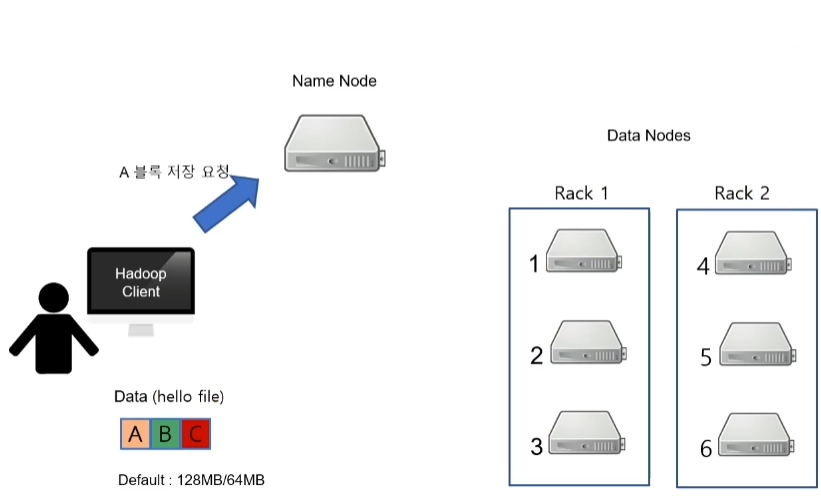
- 그러면 Name Node는 Hadoop 클라이언트에게 데이터(A)를 저장할 수 있는 공간 즉, Data Node 를 알려줍니다. 즉 사용 가능한 Data Node를 알려줍니다.
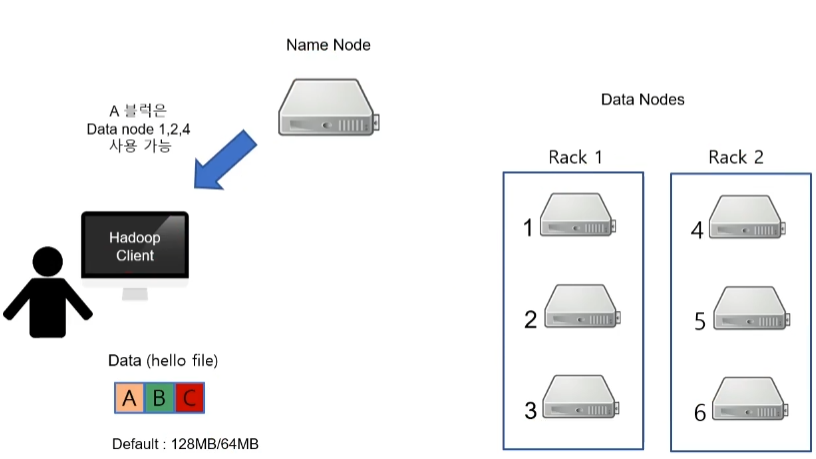
- 그러면 클라이언트는 사용가능한 목록 중에 하나를 선택해서 데이터를 보내게 됩니다.
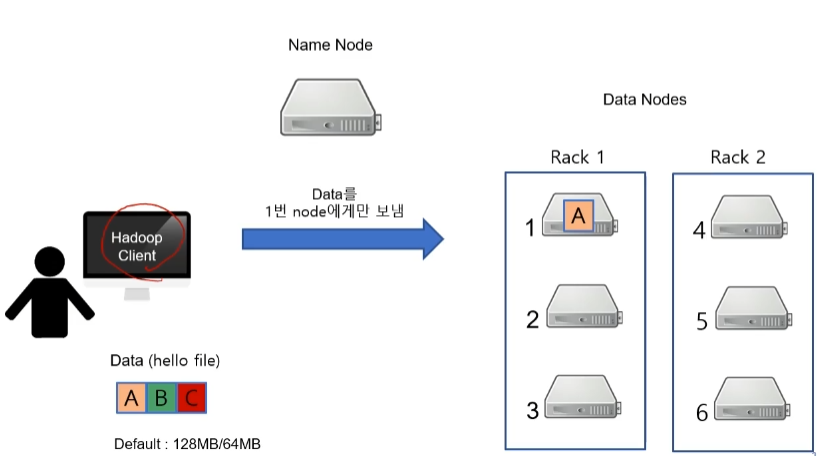
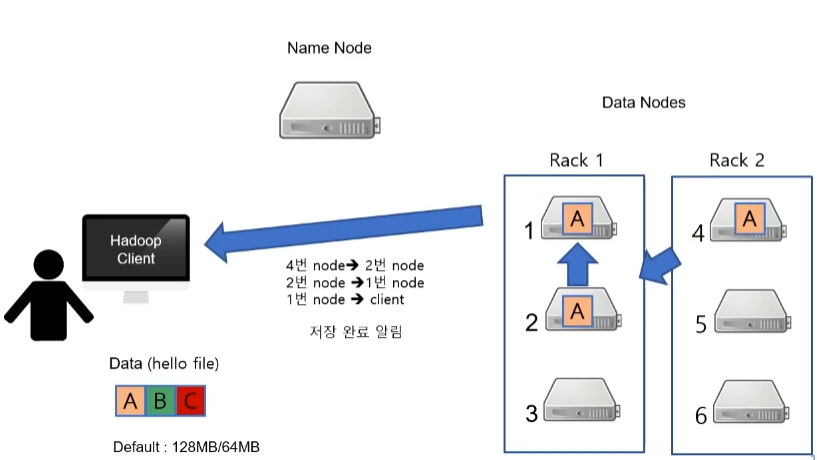
- 그러면 Data Node는 원데이터와 복사본 2개를 총 3곳에 나눠서 저장하게 됩니다. 예를들어, 1번 Data Node는 2번 node에게 그리고 2번 노드는 4번 노드에게 Data A 를 보냅니다.

- 그 후 다시 노드 4번이 노드 2번에게 그리고 노드 2번이 노드 1번에게 저장 완료를 알리면 최종적으로 노드 1번이 하둡 클라이언트에게 저장완료를 알리게 됩니다.
그러면 이제 데이터 B를 저장하겠다고 가정해 보겠습니다. 하지만 데이터 A와는 달리 Data Node가 죽었다고 가정해 보겠습니다. 즉, Name Node는 Data Node로부터 Heart beat를 주기적으로 받는데, 만약 오지 않는다면 죽었다고 가정합니다.

클라이언트가 Name Node에게 요청을 보냈는데, Name Node가 사용가능한 목록을 확인하던 도중에 Data Node 3번의 Heart beat가 오지 않음을 확인하고 죽었다고 판단합니다. 그래서 3번 노드를 제외한 노드를 클라이언트에 알려주게 됩니다.

그래서 Name Node는 클라이언트에게 3번 데이터 노드를 제외한 4, 5, 1를 알려주게 됩니다.

그러면 클라이언트는 데이터 B를 4, 5, 1중에서 4번노드에 먼저 저장하게 됩니다.

4번 노드에 원본데이터가 저장되고 복사본 2개가 5번 그리고 1번 노드에 저장됩니다. 즉, 4번 노드는 5번 노드에게 5번 노드는 1번 노드에게 Data를 보냅니다.
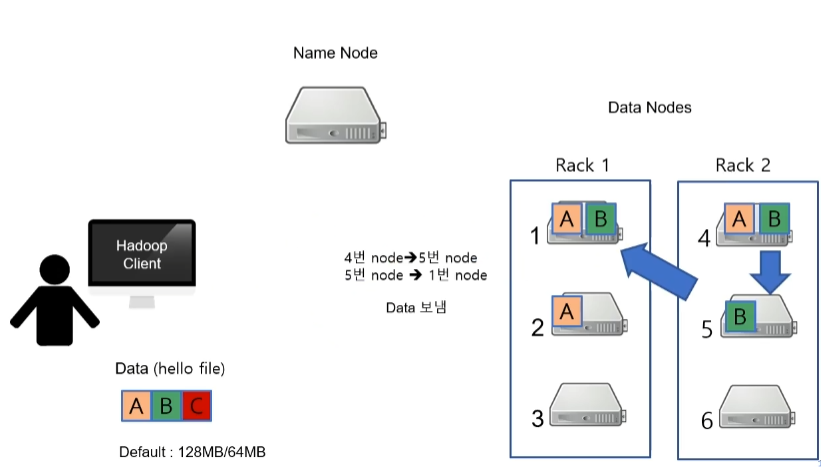
1번 노드까지 데이터가 보내지면, 다시 1번 노드는 5번노드에게 5번 노드는 4번 노드에게 그리고 최종적으로 4번 노드는 하둡 클라이언트에게 저장 완료 알림을 보내게 됩니다.

데이터 C를 저장하는 과정도 똑같다고 생각하시면 됩니다. Name Node에는 저장 위치가 다음과 같이 저장됩니다.
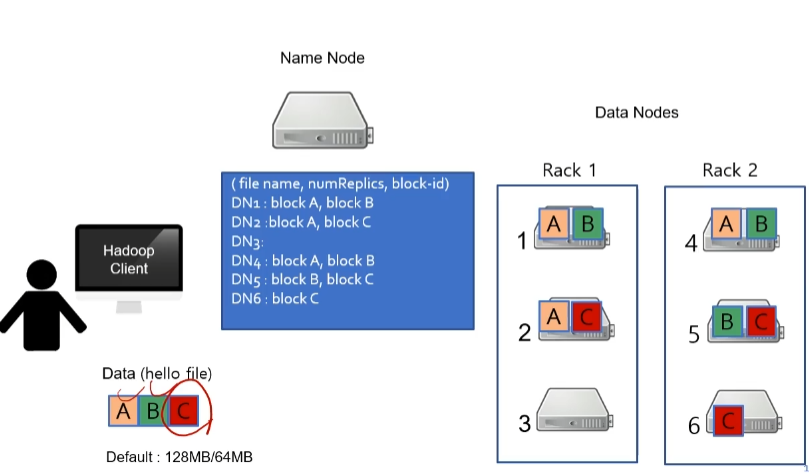
그럼이제 HDFS FILE READ에 대해서 알아보도록 하겠습니다.
HDFS FILE READ
- 먼저, 클라이언트는 Name Node에게 데이터를 읽기 요청을 보냅니다.

- Name Node가 클라이언트로부터 요청을 받으면 목록을 읽어서 다음과 같은 형태로 클라이언트에게 보내줍니다.
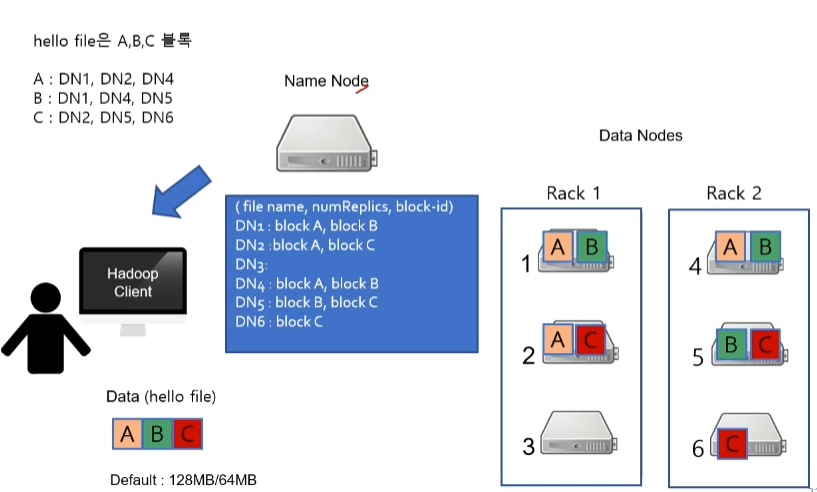
- 그러면 클라이언트는 확인 후 병렬로 데이터를 읽게 됩니다. 이때, 데이터 A와 B가 저장된 곳은 아무런 문제가 없는데 데이터 C가 저장된 곳이 올바르지 않다고 가정해 봅시다.
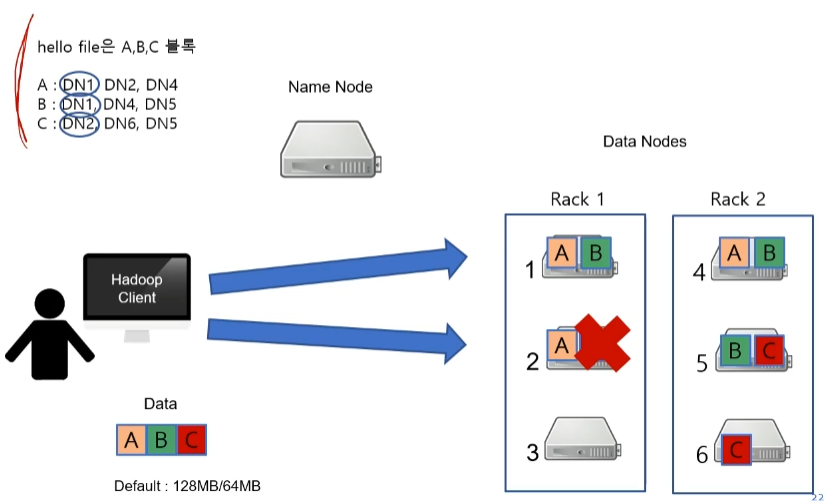
C가 저장된 Data Node 2번이 올바르지 않다면 다른 데이터 노드를 찾아서 데이터를 가져오면 됩니다.

여기서는 DN2가 올바르지 못해 DN6에서 데이터 C를 읽어오게 됩니다.
MapReduce
MapReduce는 HDFS에 나눠 저정된 파일의 분산 처리를 위한 모델입니다. 대용량 데이터를 빠르고 안전하게 처리하기 위해 개발 되었으며, JAVE, C++언어에서 적용 가능합니다. 따라서 MapReduce 알고리즘에 맞게 분석 프로그램을 개발하면, 데이터의 입출력과 병렬 처리 등 기반 작업을 프레임워크가 알아서 처리해 줍니다.
Map과 Reduce 함수 기반으로 구성되어 있습니다.
- Map - 흩어져있는 데이터를 key/value 형태로 연관성있는 데이터 분류로 묶는 작업
- Reduce - Map에서 출력된 데이터 중에 중복데이터를 제거하고 원하는 데이터를 추출하는 작업
- input -> Spliting -> Mapping -> shuffling -> Reducing -> Final Result 과정으로 진행

Hadoop Ecosystem

다양한 Hadoop 서브 프로젝들의 모임입니다.
- Hadoop 코어 프로젝트 - HDFS(분산 데이터 저장) + MapReduce(분산 처리)
- Hadoop 서브 프로젝트 - 데이터 마이닝, 수집, 분석 등 수행
분산 코디네이터: Zookeeper
- 하나의 서버에만 서비스가 집중되지 않도록, 서비스를 분산시킴
- 하나의 서버에서 처리한 결과를 다른 서버들과 동기화
- Active 서버에 문제가 발생하여 서비스를 제공할 수 없는 경우, 다른 대기중인 서버를 active 서버로 변경하여 서비스를 중단 없이 제공
- 분산 환경을 구성하는 서버들의 환경설정을 통합적으로 관리
워크 플로우 관리: Oozie, Ambari
- Oozie - Hadoop 작업을 관리하는 워크 플로우 및 코디네이터 시스템, Java web Application 서버, MapReduce 또는 Pig 작업 같은 워크 플로우를 제어
- Ambari - 웹 기반의 관리, 모니터링 툴, 사용자에게 웹UI를 제공하여 Hadoop 관리를 단순화함
정형 데이터 수집: Scoop
- 대용량 데이터 전송 솔루션, HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송하는데 사용한다. MySQL, PostgresSql과 같은 오픈소스 RDBMS를 지원함.
비정형 데이터 수집: Flume
- 비정형 데이터 수집기(로그 수집기)
- 여러 서버에 분산되어 있는 많은 양의 로그 데이터를 한 곳으로 모음
- 마스터 서버가 데이터를 수집할 위치, 전송방식, 저장할 위치를 동적으로 변경할 수 있음.
메타 데이터 관리: HCatalog
- Hadoop으로 생성한 데이터를 위한 테이블 및 스토리지 관리 서비스
- Hadoop Ecosystem간의 상호 운영성을 향상 시킴 -> Hive에서 생성한 데이터 모델을 Pig, MapReduce에서 사용가능하도록 함
데이터 분석: Pig, Hive
- Pig - 대용량 데이터를 다루기 위한 스크립트 언어, MapReduce의 단점을 보완하기 위하여 개발, JOIN 연산 지원, Pig latin 이라는 자체 언어 제공
- Hive - 데이터 웨어하우스용 솔루션, SQL과 흡사한 HiveQL을 제공, HiveQL로 정의한 내용을 MapReduce Job으로 변환하여 실행
데이터 마이닝: Mahout
- Hadoop 기반으로 데이터 마이닝 알고리즘을 구현한 오픈소스, Classification, Clustering, Recommenders/Collaborative Filtering 과 같은 다양한 알고리즘을 지원
분산 데이터베이스: HBase
- HDFS 기반의 Column Store
- 실시간 랜덤 조회 및 업데이트 가능
- Data consistency 제공
데이터 직렬화: Abro
- Binary 포맷으로 데이터를 직렬화 한다.
- JSON을 이용해 데이터 형식과 프로토콜을 정의
- RPC(Remote Procedure Call)와 데이터 직렬화를 지원하는 프레임워크
Simple Quiz
1. Hadoop ecosystem 의 각 component 에 대해, 그것이 어떤 기능을 하는가를 간략하게기술하시오 (예: 직렬화, 워크플로우 관리)
① Zookeeper
② Oozie
③ Hive
④ Mahout
⑤ Flume
2. HDFS 에서 파일을 읽는 과정을 순서대로 기술하시오.
3. MapReduce 프로그래밍 모델에서 map 함수와 reduce 함수가 수행하는 작업을 예를 들어 설명하시오.